此专栏所有文章均建议配合阅读官方Notes观看,请不要直接阅读此文而不读Notes,这样你将错失阅读官方文档的机会,非常可惜。我坚信掌握知识点固然重要,但英文文档的阅读能力本身就是迈向成熟开发者的必经之路。请不要忘记,这个专栏是希望为你以及后来者能够更好的理解课程中较为抽象的一些概念,而不是希望你失去得到训练的机会。Please keep this in mind as you navigate this challenging yet rewarding journey.
1. 数据库管理系统 (DBMS) 概览
数据库(Database)是一个相互关联的数据的集合,用于表示现实世界中的某些层面(例如:学生的记录、医院的医疗记录)。
数据库管理系统 (DBMS) 是一种用于管理数据库的软件,它允许用户
- 定义 (Define):描述数据结构和类型。
- 构造 (Construct):在存储介质上存储数据。
- 操纵 (Manipulate):对数据进行查询、更新和删除。
1.1为什么要使用 DBMS?(而非直接存储在文件系统中)
在早期的应用中,数据直接存储在操作系统文件中(如 CSV)。这种方式存在以下严重缺陷:
- 数据冗余与不一致:相同的信息在不同文件中重复,导致更新困难。
- 数据访问困难:必须为每个新任务编写专门的应用程序。
- 数据孤立:数据格式不统一,分布在不同物理位置。
- 完整性问题:难以实施跨实体的硬性约束(例如:年龄不能为负数)。
- 原子性问题:程序崩溃时可能导致数据处于半更新状态。
- 并发访问:多个用户同时读写会导致数据冲突。
- 安全性:难以精细化控制谁能查看哪些数据。
2. 关系模型 (The Relational Model)
1970 年,IBM 研究员 Ted Codd 意识到数据访问与物理布局耦合太紧。他提出了关系模型,旨在实现数据独立性 (Data Independence)。
2.1核心定义:
- 结构 (Structure):关系的定义及其包含的属性。
- 完整性 (Integrity):确保数据满足特定约束(如:主键约束)。
- 操纵 (Manipulation):如何访问或修改数据。
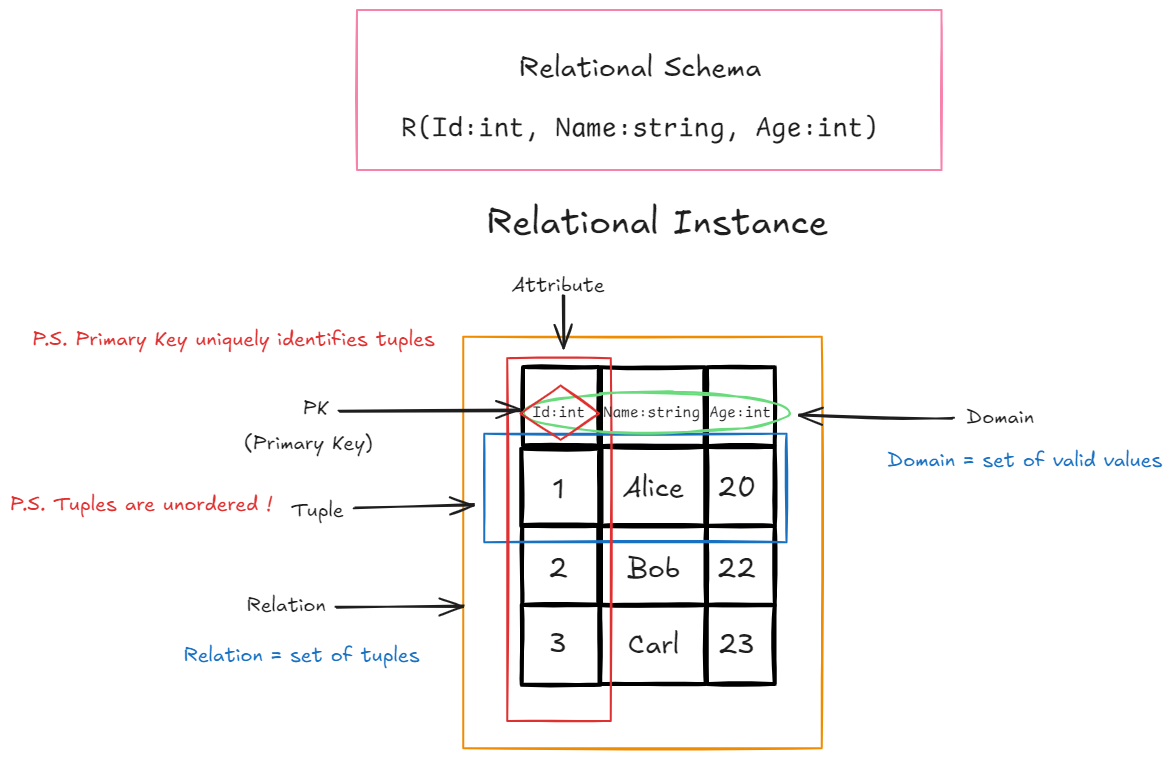
2.2关系的组成要素:
- 关系 (Relation):元组的无序集合。
- 元组 (Tuple):关系中的一行。它是属性值的集合。
- 属性 (Attribute):关系中的一列,具有唯一的名称。
- 域 (Domain):属性的可取值范围(数据类型)。
- 关系模式 (Relational Schema):对关系的描述。表示为 。
- 关系实例 (Relational Instance):在特定时刻,关系中具体的数据集合。
3. 关系代数 (Relational Algebra)
关系代数是一种过程式 (Procedural) 查询语言。它由一组运算符组成,这些运算符以一个或多个关系作为输入,并产生一个新的关系作为输出。
基本运算符 (Fundamental Operators):
| 运算符 | 符号 | 描述 | SQL 等价项 |
|---|---|---|---|
| 选择 (Select) | 根据条件选择行。 | WHERE | |
| 投影 (Project) | 选择特定的列并去重。 | SELECT | |
| 并 (Union) | 返回出现在任一关系中的所有元组。 | UNION | |
| 差 (Difference) | 返回在第一个关系中但不在第二个中的元组。 | EXCEPT | |
| 交 (Intersection) | 返回同时出现在两个关系中的元组。 | INTERSECT | |
| 笛卡尔积 (Product) | 返回两个关系所有元组的配对组合。 | CROSS JOIN | |
| 连接 (Join) | 结合两个关系中满足匹配条件的元组。 | JOIN |
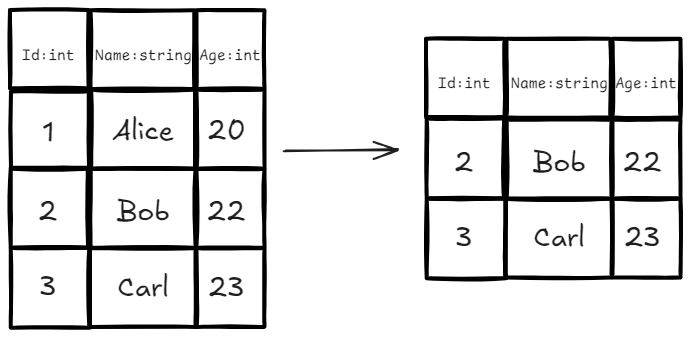
3.1 Select
定义:基于给定的谓词(Predicate,即过滤条件),从关系中选出符合条件的元组(行)。
- 实例:我们想选出所有年龄(Age)大于 21 岁的学生。
- 代数表达式:
- SQL 对应:
SELECT * FROM R WHERE Age > 21;
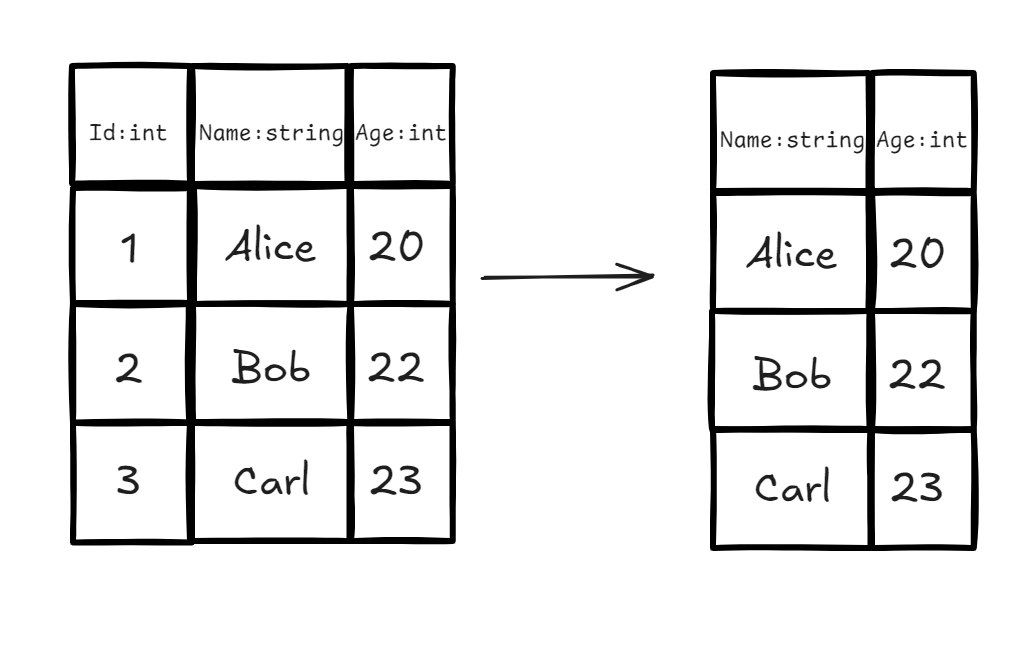
3.2 Project
定义:从关系中选出指定的属性(列),并生成一个新的关系。它本质上是改变关系的模式(Schema)。
- 实例:我们只想要学生的姓名(Name)和年龄(Age),不想要 ID。
- 代数表达式:
- SQL 对应:
SELECT Name, Age FROM R;
3.3 Union
定义:将两个具有相同模式(Schema) 的关系合并,输出一个包含两个关系中所有元组的新关系。它会自动去除重复的元组。
前提条件(Union-Compatible):参与运算的两个关系必须拥有相同数量的属性,且对应位置属性的域(Domain)必须相同。
- 实例:我们有两份学生名单 (校本部学生)和 (分校区学生),现在需要一份全校学生的总名单。
- 代数表达式:
- SQL 对应:
SELECT * FROM R UNION SELECT * FROM S;注意:SQL 的UNION默认去重,如果不去重则使用UNION ALL

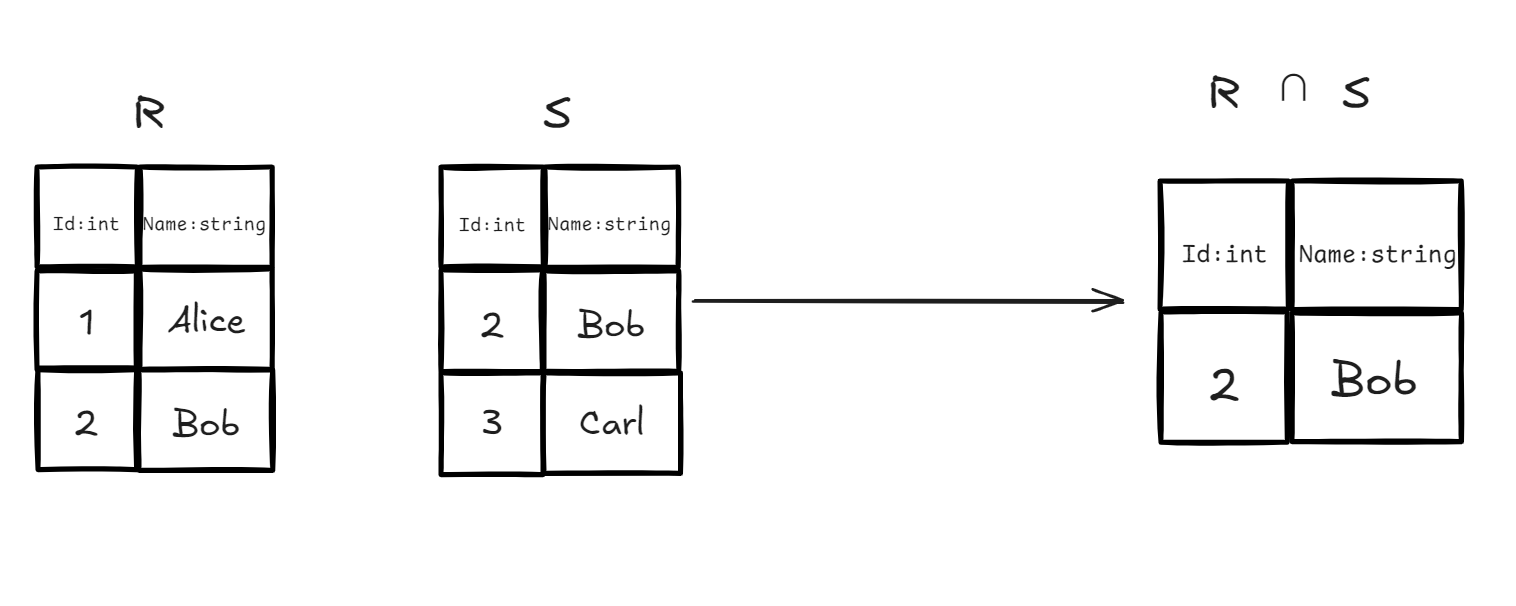
3.4 Intersection
定义:选出同时存在于两个关系中的元组,并生成一个新的关系。
前提条件:满足 Union-Compatible。
- 实例:我们有关系 (校本部学生)和关系 (分校区学生),现在需要找出那些同时在两个校区都有登记的学生名单。
- 代数表达式:
- SQL 对应:
SELECT * FROM R INTERSECT SELECT * FROM S;
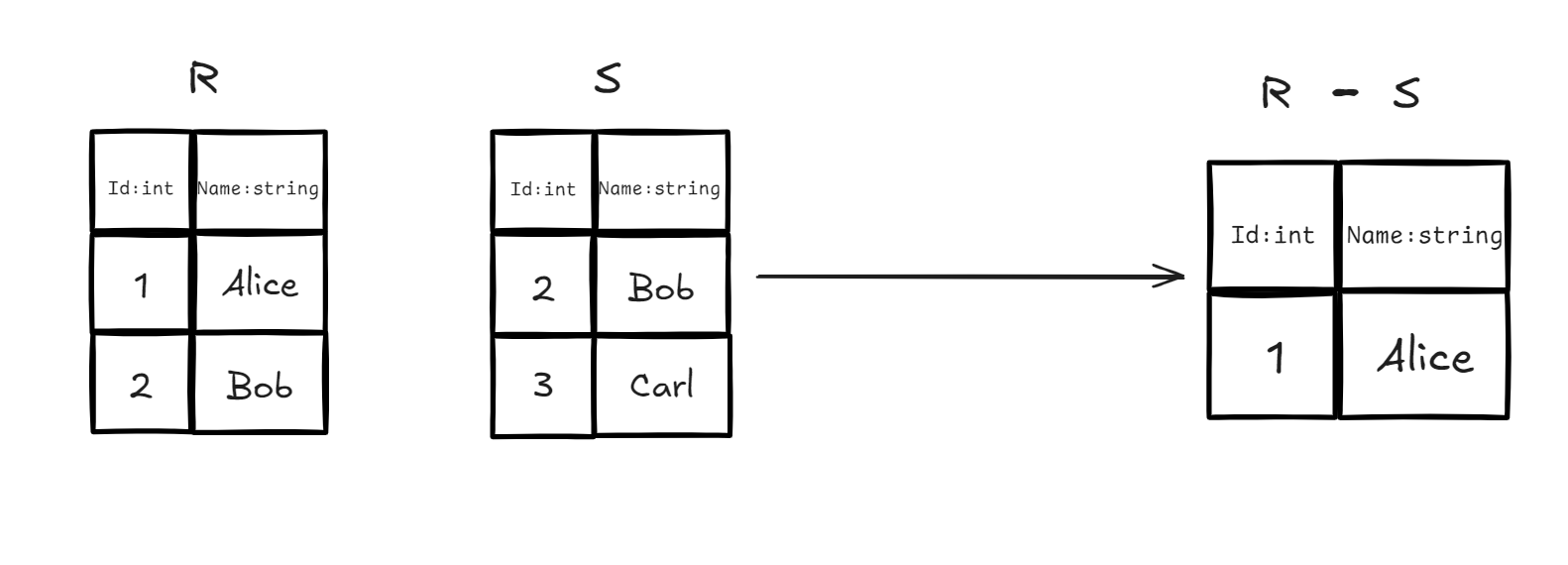
3.4 Difference
定义:从第一个关系中去掉那些也出现在第二个关系中的元组。简单来说,就是「属于 但不属于 」的部分。
前提条件:满足 Union-Compatible。
注意:差运算是不满足交换律的, 与 的结果通常不同。
- 实例:我们有关系 (校本部学生)和关系 (分校区学生),现在需要找出那些仅在校本部登记、没有在分校区登记的学生名单。
- 代数表达式:
- SQL 对应:
SELECT * FROM R EXCEPT SELECT * FROM S;(在 MySQL 中通常使用LEFT JOIN配合WHERE S.Id IS NULL来实现)
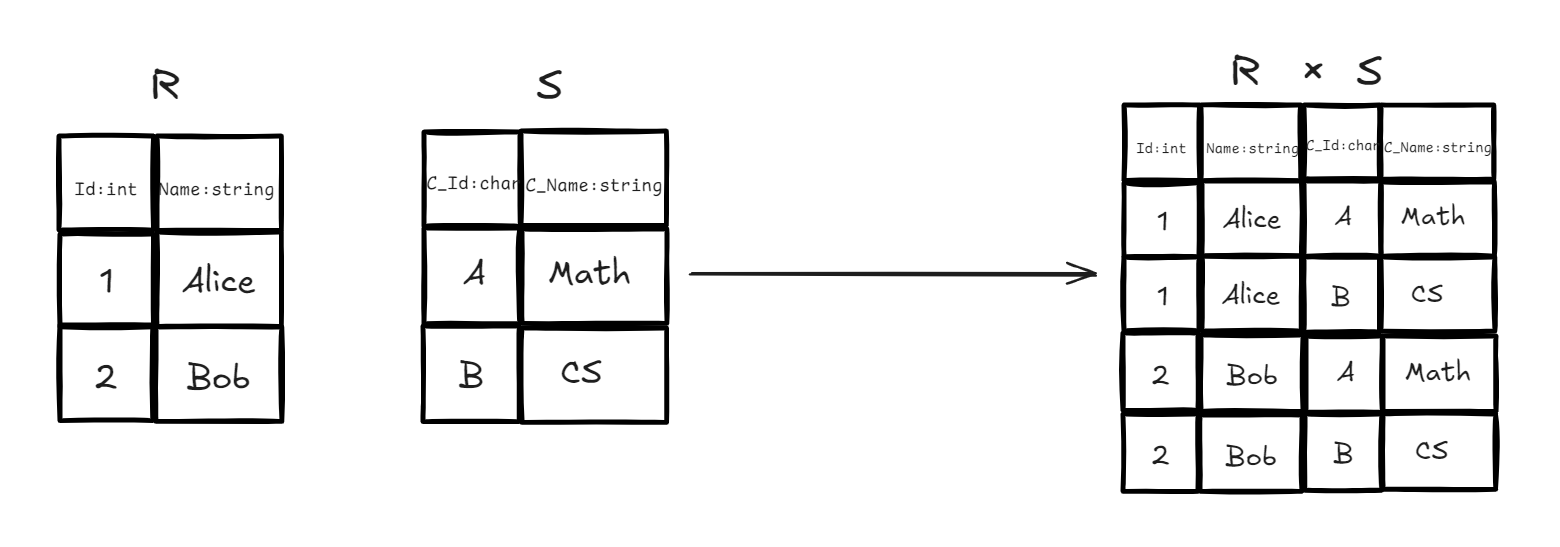
3.5 Cartesian Product
定义:将两个关系中的元组进行全排列组合。结果中的每一个元组都是由第一个关系的一个元组与第二个关系的一个元组拼接而成。
属性变化:如果关系 有 个属性,关系 有 个属性,那么 的结果将有 个属性。
基数变化:如果 有 行, 有 行,结果将有 行。
- 实例:我们有关系 (学生表)和关系 (课程表),现在需要生成一份所有学生选修所有课程的可能组合清单。
- 代数表达式:
- SQL 对应:
SELECT * FROM R CROSS JOIN S;或者SELECT * FROM R, S;
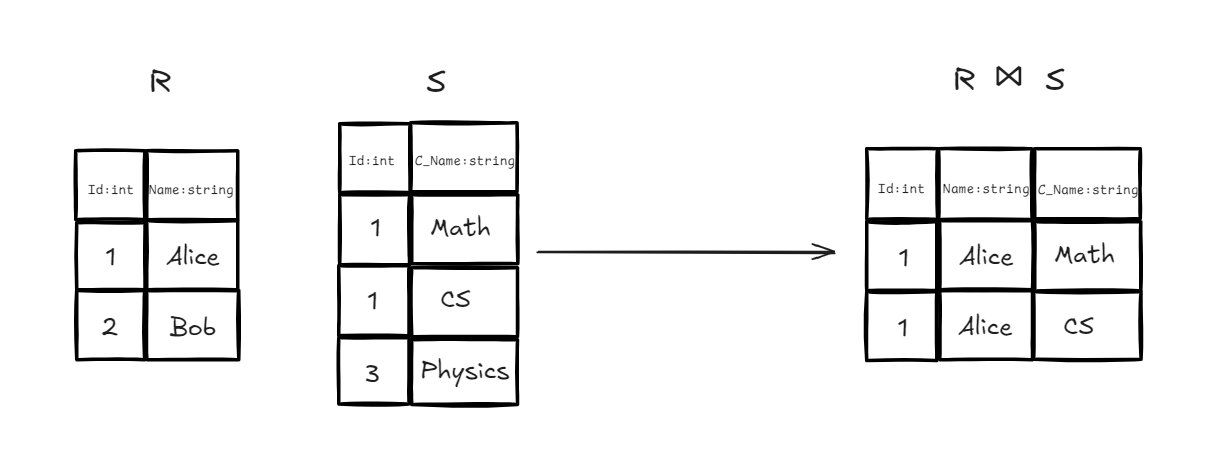
3.6 Join
定义:将两个关系中在同名属性(Common Attributes) 上取值相等的元组拼接在一起。它会自动合并掉重复的列。
逻辑本质:它是「笛卡尔积」的优化版。它先做笛卡尔积,然后挑选出同名列数值相等的行,最后再用投影去掉重复的列。
- 实例:我们有学生表 和选课表 ,两表都有
Id这一列。我们想知道每个学生具体选了什么课。 - 代数表达式:
- SQL 对应:
SELECT * FROM R NATURAL JOIN S;或SELECT * FROM R JOIN S USING (Id);